
O Soneto Claude 3.5 da Anthropic atualmente está no topo do S&P AI Benchmarks by Kensho, uma avaliação rigorosa de modelos de linguagem grande (LLMs) para finanças e negócios. Kensho, o Hub de Inovação em IA da S&P Global, utilizando o Amazon Bedrock, conseguiu executar rapidamente o Claude 3.5 Sonnet da Anthropic em um conjunto desafiador de tarefas comerciais e financeiras.
A AuraMind, que integra o Claude 3.5 como um de seus modelos, se beneficia diretamente dessas capacidades avançadas, garantindo uma performance de ponta em ambientes corporativos. No workshop de IA Generativa, destacaremos como a AuraMind, através do Claude 3.5, oferece soluções inovadoras e eficazes para os desafios empresariais contemporâneos. Discutimos essas tarefas e as capacidades do Soneto Claude 3.5 da Anthropic neste post, e como elas se traduzem em vantagens concretas para os usuários da AuraMind.
Limitações das avaliações de LLM
É uma prática comum usar testes padronizados, como o Massive Multitask Language Understanding (MMLU, um teste que consiste em questões de múltipla escolha que abrangem 57 disciplinas como matemática, filosofia e medicina) e o HumanEval (teste de geração de código), para avaliar LLMs. Embora essas avaliações sejam úteis para dar aos usuários de LLM uma noção do desempenho relativo de um LLM, elas têm limitações. Por exemplo, pode haver vazamento de perguntas e respostas de conjuntos de dados de benchmark em dados de treinamento.
Além disso, os LLMs atuais funcionam bem para tarefas gerais, como tarefas de resposta a perguntas e geração de código. No entanto, esses recursos nem sempre se traduzem em tarefas específicas do domínio. No setor de serviços financeiros, ouvimos os clientes perguntarem qual modelo escolher para seus aplicativos de inteligência artificial (IA) generativa de domínio financeiro. Esses aplicativos exigem que os LLMs tenham o conhecimento de domínio necessário e sejam capazes de raciocinar sobre dados numéricos para calcular métricas e extrair insights. Também ouvimos de clientes que LLMs de referência geral altamente classificados não necessariamente fornecem o melhor desempenho para seus aplicativos financeiros e de negócios.
Nossos clientes frequentemente nos perguntam se temos um benchmark de LLMs apenas para o setor financeiro que poderia ajudá-los a escolher os LLMs certos mais rapidamente.
Benchmarks de S&P AI por Kensho
Quando o laboratório de pesquisa e desenvolvimento da Kensho começou a pesquisar e desenvolver conjuntos de dados úteis e desafiadores para finanças e negócios, rapidamente ficou claro que, dentro do setor financeiro, havia uma escassez de avaliações tão realistas. Para enfrentar esse desafio, o laboratório criou o S&P AI Benchmarks, que visa servir como padrão da indústria para modelos de benchmarking para finanças e negócios.
"Ao oferecer uma solução de benchmarking robusta e independente, queremos ajudar o setor de serviços financeiros a tomar decisões inteligentes sobre quais modelos implementar para quais casos de uso."
– Bhavesh Dayalji, diretor de IA da S&P Global e CEO da Kensho.
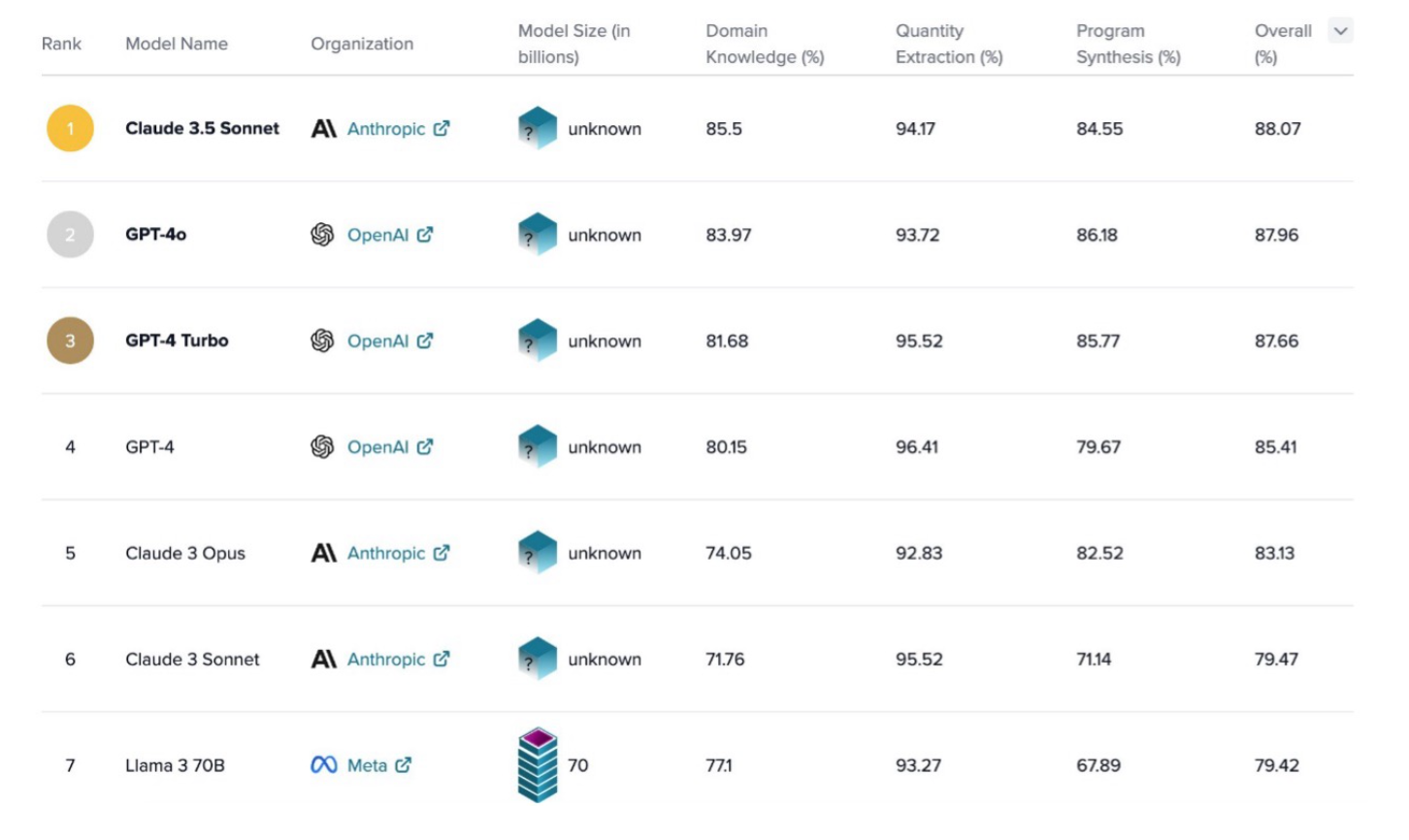
O S&P AI Benchmarks se concentra em medir a capacidade dos modelos de executar tarefas que se concentram em três categorias de capacidades e conhecimento: conhecimento de domínio, extração de quantidade e raciocínio quantitativo (mais detalhes podem ser encontrados neste artigo). Este recurso disponível publicamente inclui uma tabela de classificação correspondente, que permite que todos vejam o desempenho de cada modelo de linguagem de última geração que foi avaliado nessas tarefas rigorosas. O Soneto Claude 3.5 da Anthropic está atualmente em primeiro lugar (em julho de 2024), demonstrando os pontos fortes da Anthropic no domínio de negócios e finanças.
A Kensho optou por testar seu benchmark com o Amazon Bedrock por causa de sua facilidade de uso e controles de segurança e privacidade prontos para empresas.
As tarefas de avaliação
A S&P AI Benchmarks avalia LLMs usando uma ampla gama de questões relacionadas a finanças e negócios. A avaliação é composta por 600 questões que abrangem três categorias: domínio conhecimento, extração quantitativa e raciocínio quantitativo. Cada pergunta foi verificada por especialistas do domínio e profissionais de finanças com mais de 5 anos de experiência.
Raciocínio Quantitativo
Essa tarefa determina se, dada uma pergunta e documentos longos, o modelo pode executar cálculos complexos e raciocinar corretamente para produzir uma resposta precisa. As perguntas são escritas por profissionais financeiros usando dados do mundo real e conhecimento financeiro. Como tal, eles estão mais próximos dos tipos de perguntas que os profissionais de negócios e financeiros fariam em um aplicativo de IA generativa. Veja a seguir um exemplo:
Pergunta: O preço de mercado das ações ordinárias da K-T-Lew Corporation é de US$ 60 por ação, e cada ação dá ao seu proprietário um direito de subscrição. Quatro direitos são necessários para comprar uma ação ordinária adicional ao preço de subscrição de US$ 54 por ação. Se as ações ordinárias estão atualmente vendendo direitos, qual é o valor teórico de um direito? Responda ao centavo mais próximo.
Para responder à pergunta, os LLMs devem resolver referências de quantidades complexas e usar conhecimentos financeiros implícitos. Por exemplo, "direito de assinatura", "direitos de venda" e "preço de assinatura" na pergunta anterior exigem conhecimento financeiro para entender os termos. Para gerar a resposta, os LLMs precisam ter o conhecimento financeiro de calcular o "valor teórico de um direito".
Extração Quantitativa
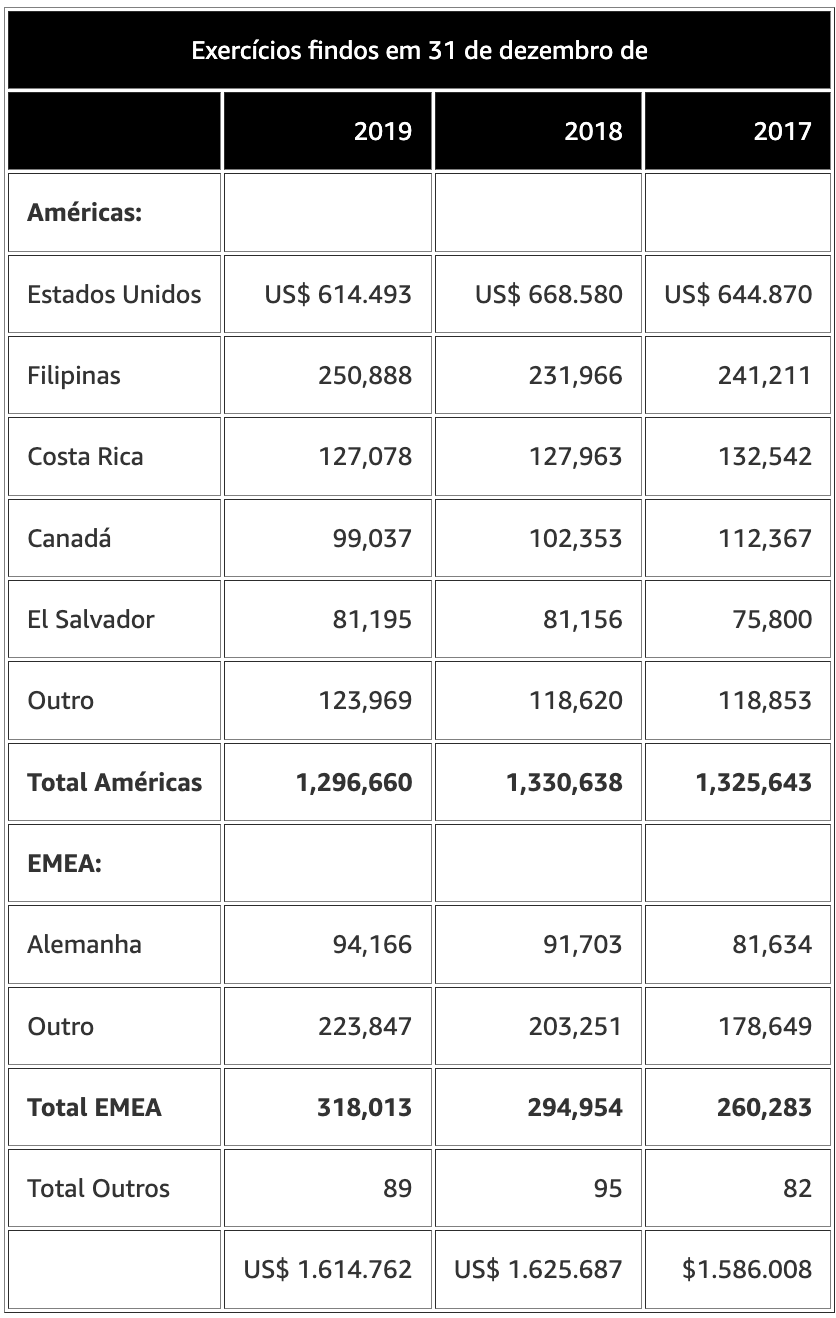
Dado relatórios financeiros, um LLM pode extrair as informações numéricas pertinentes. Muitos fluxos de trabalho de negócios e finanças exigem extração de quantidade de alta precisão. No exemplo a seguir, para que um LLM responda à pergunta corretamente, ele precisa entender que a linha da tabela representa o local e a coluna representa o ano e, em seguida, extrair a quantidade correta (valor total) da tabela com base no local e no ano solicitados:
Pergunta: Qual foi o valor total das Américas em 2019? (Mil)
Dado o Contexto: Os dez principais clientes da Empresa representaram 42,2%, 44,2% e 46,9% de suas receitas consolidadas durante os anos findos em 31 de dezembro de 2019, 2018 e 2017, respectivamente. A tabela a seguir representa uma desagregação da receita de contratos com clientes por local de entrega (em milhares).
Conhecimento de domínio
Os modelos devem demonstrar uma compreensão dos termos, práticas e fórmulas comerciais e financeiras. A tarefa é responder a perguntas de múltipla escolha coletadas dos exames práticos de CFA e dos exames de ética nos negócios, microeconomia e contabilidade profissional do conjunto de dados MMLU. Na pergunta de exemplo a seguir, o LLM precisa entender o que é um sistema de taxa fixa:
Pergunta: Um sistema de taxa fixa é caracterizado por:
A: Compromisso legislativo explícito de manter uma paridade especificada.
B: A independência monetária está sujeita à manutenção de uma paridade cambial.
C: Reservas cambiais alvo com relação direta com agregados monetários domésticos.
Soneto Claude 3.5 da Anthropic na Amazon Bedrock
Além de estar no topo do ranking S&P AI Benchmarks, o Soneto Claude 3.5 da Anthropic produz desempenho de ponta em uma ampla gama de outras tarefas, incluindo conhecimento especializado de nível de graduação (MMLU), raciocínio especializado de nível de pós-graduação (GPQA), código (HumanEval) e muito mais. Como apontado no modelo Claude 3.5 Sonnet da Anthropic agora disponível no Amazon Bedrock: Ainda mais inteligência do que Claude 3 Opus a um quinto do custo, o Claude 3.5 Sonnet da Anthropic fez melhorias importantes no processamento visual e compreensão, escrita e geração de conteúdo, processamento de linguagem natural, codificação e geração de insights.
Leaderbord
Comece a usar o Soneto Claude 3.5 da Anthropic no Amazon Bedrock
O Soneto Claude 3.5 da Anthropic está disponível em geral no Amazon Bedrock como parte da família Claude de modelos de IA da Anthropic. O Amazon Bedrock é um serviço totalmente gerenciado que oferece acesso rápido a uma variedade de LLMs líderes do setor e outros modelos de fundação da AI21 Labs, Anthropic, Cohere, Meta, Stability AI e Amazon. Ele também oferece um amplo conjunto de recursos para criar aplicativos de IA generativos, simplificando o desenvolvimento e, ao mesmo tempo, apoiando a privacidade e a segurança. Dezenas de milhares de clientes já selecionaram o Amazon Bedrock como base para sua estratégia de IA generativa. Clientes do setor financeiro, como Nasdaq, NYSE, Broadridge, Jefferies, NatWest e muito mais, usam o Amazon Bedrock para criar seus aplicativos de IA generativa.
"A equipe da Kensho usa o Amazon Bedrock para avaliar rapidamente modelos de vários provedores diferentes. Na verdade, o acesso ao Amazon Bedrock permitiu que a equipe comparasse o Soneto Claude 3.5 da Anthropic em 24 horas."
– Diana Mingels, Chefe de Machine Learning da Kensho.
Conclusão
Neste post, mostramos os detalhes da tarefa S&P AI Benchmarks para negócios e finanças. O benchmark mostra que o Soneto Claude 3.5 da Anthropic é o principal executante nessas tarefas. Para começar a usar esse novo modelo, veja os modelos Claude da Anthropic. Com o Amazon Bedrock, você obtém um serviço totalmente gerenciado que oferece acesso aos principais modelos de IA de empresas como AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI e Amazon por meio de uma única API, juntamente com um amplo conjunto de recursos para criar aplicativos de IA generativos. Saiba mais e comece hoje mesmo no Amazon Bedrock.
